Publications
* Equal Contribution | † Corresponding Author
Video Large Language Model
-
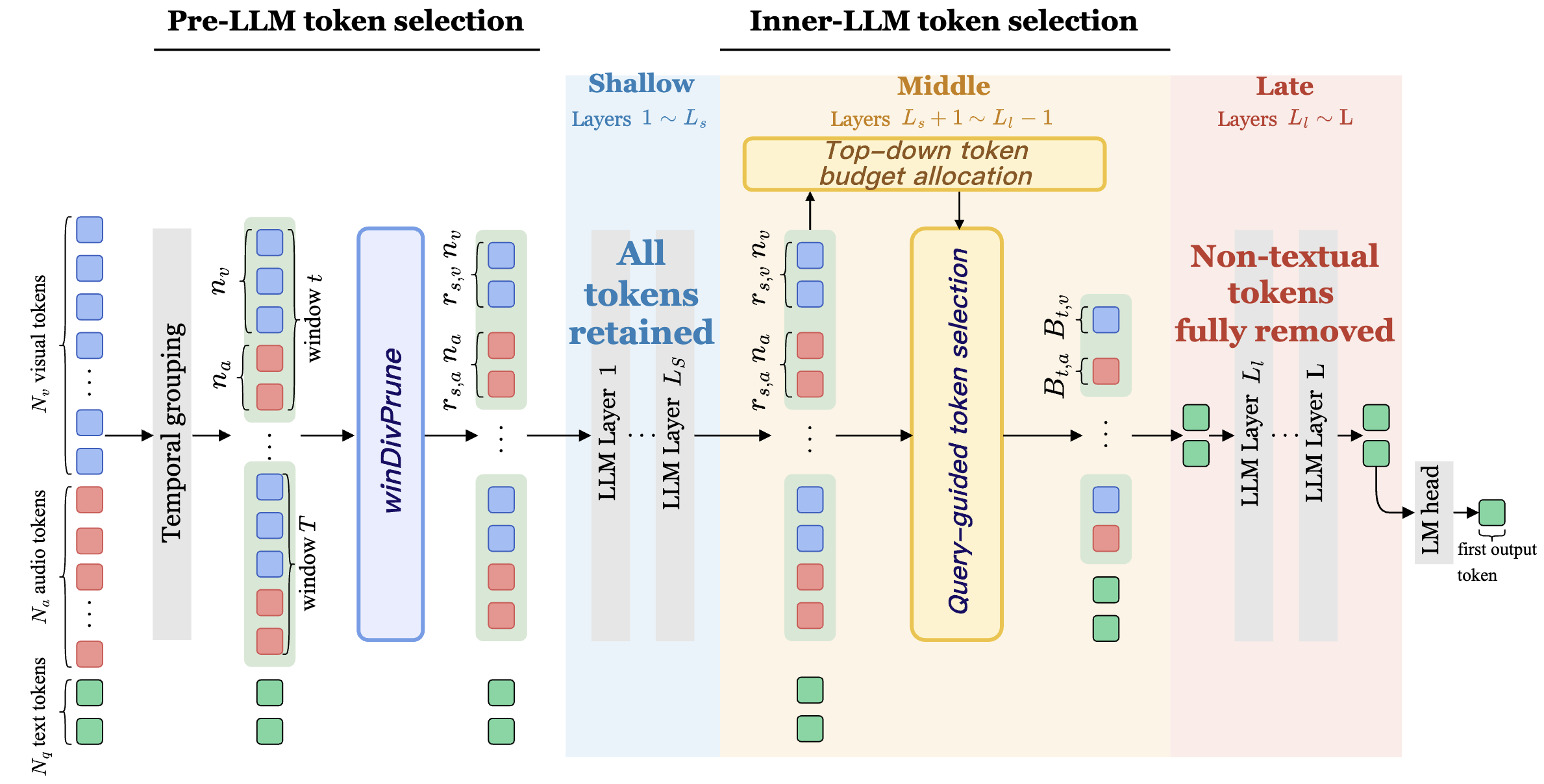 Stage-adaptive Token Selection for Efficient Omni-modal LLMspreprint arXiv:2605.20035, 2026
Stage-adaptive Token Selection for Efficient Omni-modal LLMspreprint arXiv:2605.20035, 2026Omni-modal large language models (om-LLMs) achieve unified audio-visual understanding by encoding video and audio into temporally aligned token sequences interleaved at the window level. However, processing these dense non-textual tokens throughout the LLM incurs substantial computational overhead. Although training-free token selection can reduce this cost, existing methods either focus on visual-only inputs or prune om-LLM tokens only before the LLM with fixed per-modality ratios, failing to capture how cross-modal token importance evolves across layers. To address this limitation, we first analyze the layer-wise token dependency of om-LLMs. We find that visual and audio dependencies follow a block-wise pattern and gradually weaken with depth, indicating that many late-layer non-textual tokens become redundant after cross-modal fusion. Motivated by this observation, we propose SEATS, a training-free, stage-adaptive token selection method for efficient om-LLM inference. Before the LLM, SEATS removes spatiotemporal redundancy via attention-weighted diversity selection. Inside the LLM, it progressively prunes tokens across blocks and dynamically allocates the retention budget from temporal windows to modalities using query relevance scores. In late layers, it removes all remaining non-textual tokens once cross-modal fusion is complete. Experiments on Qwen2.5-Omni and Qwen3-Omni demonstrate that SEATS effectively improves inference efficiency. Retaining only 10% of visual and audio tokens, it achieves a 9.3\times FLOPs reduction and a 4.8\times prefill speedup while preserving 96.3% of the original performance.
-
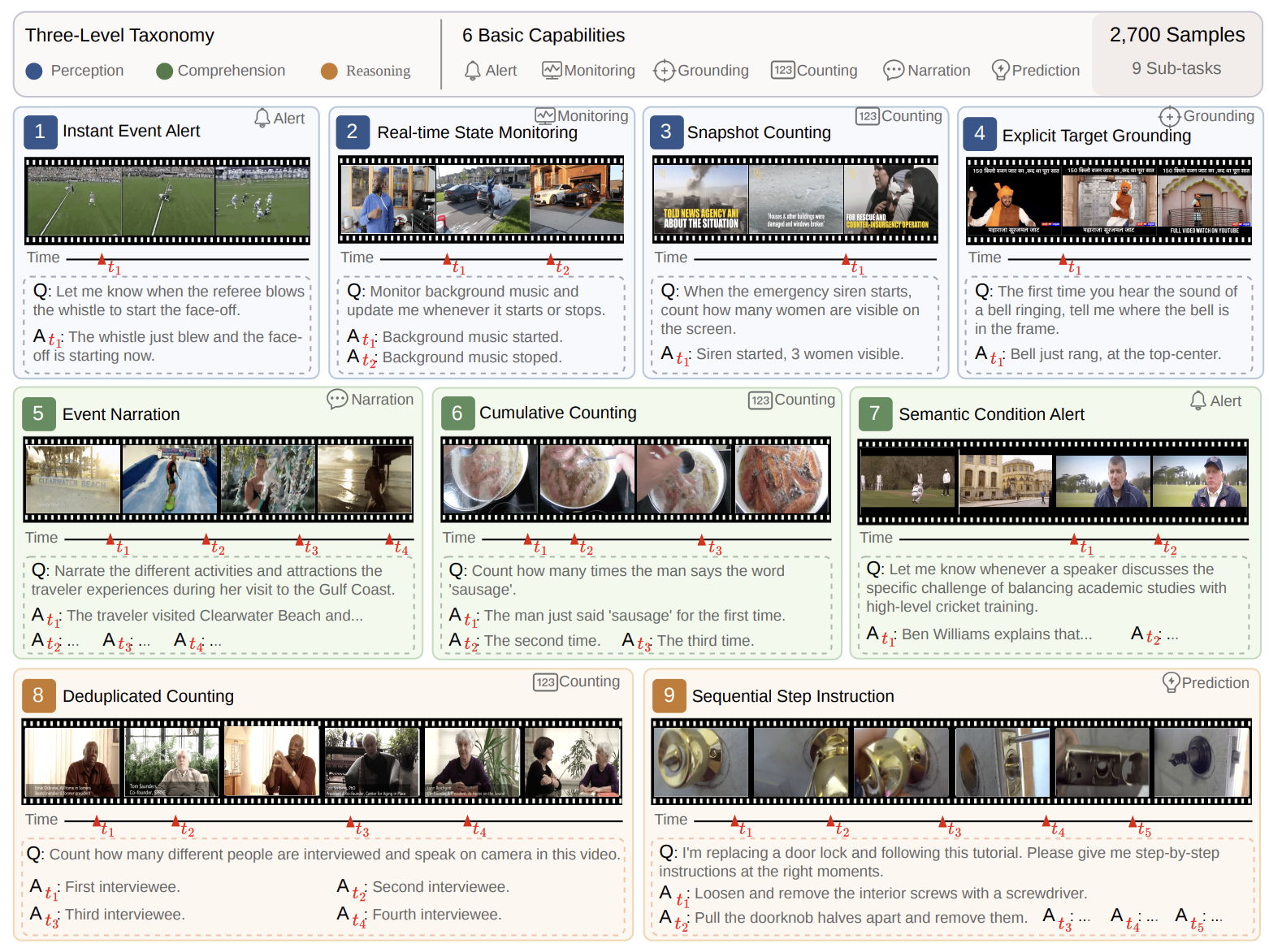 OmniPro: A Comprehensive Benchmark for Omni-Proactive Streaming Video Understandingpreprint arXiv:2605.18577, 2026
OmniPro: A Comprehensive Benchmark for Omni-Proactive Streaming Video Understandingpreprint arXiv:2605.18577, 2026Omni-proactive streaming video understanding, i.e., autonomously deciding when to speak and what to say from continuous audio-visual streams, is an emerging capability of omni-modal large language models. Existing benchmarks fall short in three key aspects: they rely primarily on visual signals, adopt polling or fixed-timestamp protocols instead of true proactive evaluation, and cover only a limited range of tasks, preventing reliable assessment and differentiation of omni-proactive streaming models. We present OmniPro, the first benchmark to jointly evaluate omni-modal perception, proactive responding, and diverse video understanding tasks. It comprises 2,700 human-verified samples spanning 9 sub-tasks and 3 cognitive levels, covering 6 basic video understanding capabilities. Notably, 84% of samples require audio signals (speech or non-speech), and each sample is annotated with modality-isolation labels to enable fine-grained multimodal analysis. We further introduce a dual-mode evaluation protocol: \textitProbe mode assesses content understanding by querying the model before and after each ground-truth trigger, while \textitOnline mode evaluates full proactive ability by requiring models to autonomously decide when to respond in streaming input. Evaluating 11 representative models reveals three key findings: (1) audio provides consistent gains but with highly variable utilization across models, (2) performance degrades significantly over time, indicating limited long-horizon robustness, and (3) non-speech audio perception remains the weakest dimension.


Cross-modal Retrieval
- SAVE: Speech-Aware Video Representation Learning for Video-Text RetrievalIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
For video-text retrieval, the use of CLIP has been a de facto choice. Since CLIP provides only image and text encoders, this consensus has led to a biased paradigm that entirely ignores the sound track of videos. While several attempts have been made to reintroduce audio – typically by incorporating an audio encoder and fusing its output with visual features – these methods face two challenges: ineffective representation of speech content and suboptimal vision-audio fusion. To address these issues jointly, we propose SAVE, a Speech Aware Video rEpresentation learning method. SAVE improves upon AVIGATE, a SOTA audiovisual method, with a dedicated speech branch for more effective speech embedding. Furthermore, we introduce soft-ALBEF for early vision-audio alignment that facilitates fusion. Extensive experiments on five benchmarks show that SAVE compares favorably against the SOTA, outperforming AVIGATE by +4.1% on MSRVTT-9k, +1.9% on MSRVTT-7k, +2.5% on VATEX, +9.8% on Charades, and +2.1% on LSMDC, in light of the SumR metric.
- Music Grounding by Short VideoIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
Adding proper background music helps complete a short video to be shared. Previous work tackles the task by video-to-music retrieval (V2MR), aiming to find the most suitable music track from a collection to match the content of a given query video. In practice, however, music tracks are typically much longer than the query video, necessitating (manual) trimming of the retrieved music to a shorter segment that matches the video duration. In order to bridge the gap between the practical need for music moment localization and V2MR, we propose a new task termed Music Grounding by Short Video (MGSV). To tackle the new task, we introduce a new benchmark, MGSV-EC, which comprises a diverse set of 53k short videos associated with 35k different music moments from 4k unique music tracks. Furthermore, we develop a new baseline method, MaDe, which performs both video-to-music matching and music moment detection within a unified end-to-end deep network. Extensive experiments on MGSV-EC not only highlight the challenging nature of MGSV but also set MaDe as a strong baseline.
- Learning Partially-Decorrelated Common Spaces for Ad-hoc Video SearchFan Hu, Zijie Xin, and Xirong Li†In Proceedings of the 33rd ACM international conference on Multimedia (ACMMM), 2025
Ad-hoc Video Search (AVS) involves using a textual query to search for multiple relevant videos in a large collection of unlabeled short videos. The main challenge of AVS is the visual diversity of relevant videos. A simple query such as "Find shots of a man and a woman dancing together indoors" can span a multitude of environments, from brightly lit halls and shadowy bars to dance scenes in black-and-white animations. It is therefore essential to retrieve relevant videos as comprehensively as possible. Current solutions for the AVS task primarily fuse multiple features into one or more common spaces, yet overlook the need for diverse spaces. To fully exploit the expressive capability of individual features, we propose LPD, short for Learning Partially Decorrelated common spaces. LPD incorporates two key innovations: feature-specific common space construction and the de-correlation loss. Specifically, LPD learns a separate common space for each video and text feature, and employs de-correlation loss to diversify the ordering of negative samples across different spaces. To enhance the consistency of multi-space convergence, we designed an entropy-based fair multi-space triplet ranking loss. Extensive experiments on the TRECVID AVS benchmarks (2016-2023) justify the effectiveness of LPD. Moreover, diversity visualizations of LPD’s spaces highlight its ability to enhance result diversity.
- DAPL: Integration of Positive and Negative Descriptions in Text-Based Person SearchIn Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), 2025
Text-based person search (TBPS) aims to retrieve specific images of individuals from large datasets using textual descriptions. Existing TBPS methods focus primarily on identifying explicit positive attributes, often neglecting the critical role of negative descriptions. This oversight can lead to false positives, where images that should be excluded based on negative descriptions are incorrectly included, due to partial alignment with the positive criteria. To address this limitation, we propose the Dual Attribute Prompt Learning (DAPL) framework, which incorporates both positive and negative descriptions to improve the interpretative accuracy of vision-language models in TBPS tasks. DAPL combines Dual Image-Attribute Contrastive (DIAC) learning with Sensitive Image-Attribute Matching (SIAM) learning to enhance the detection of previously unseen attributes. Furthermore, to achieve a balance between coarse and finegrained alignment of visual and textual embeddings, we introduce the Dynamic Token-wise Similarity (DTS) loss. This loss function refines the representation of both matching and non-matching descriptions at the token level, providing more precise and adaptable similarity assessments, and ultimately improving the accuracy of the matching process. Empirical results demonstrate that DAPL outperforms state-of-the-art methods, enhancing both precision and robustness in TBPS tasks.
- Holistic Features are almost Sufficient for Text-to-Video RetrievalIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
For text-to-video retrieval (T2VR), which aims to retrieve unlabeled videos by ad-hoc textual queries, CLIP-based methods currently lead the way. Compared to CLIP4Clip which is efficient and compact, state-of-the-art models tend to compute video-text similarity through fine-grained cross-modal feature interaction and matching, putting their scalability for large-scale T2VR applications into doubt. We propose TeachCLIP, enabling a CLIP4Clip based student network to learn from more advanced yet computationally intensive models. In order to create a learning channel to convey fine-grained cross-modal knowledge from a heavy model to the student, we add to CLIP4Clip a simple Attentional frame-Feature Aggregation (AFA) block, which by design adds no extra storage / computation overhead at the retrieval stage. Frame-text relevance scores calculated by the teacher network are used as soft labels to supervise the attentive weights produced by AFA. Extensive experiments on multiple public datasets justify the viability of the proposed method. TeachCLIP has the same efficiency and compactness as CLIP4Clip, yet has near-SOTA effectiveness.





Medical AI
-
 Fundus-R1: Training a Fundus-Reading MLLM with Knowledge-Aware Reasoning on Public DataYuchuan Deng, Qijie Wei, Kaiheng Qian, Jiazhen Liu, Zijie Xin, Bangxiang Lan, Jingyu Liu, and 2 more authorspreprint arXiv:2604.08322, 2026
Fundus-R1: Training a Fundus-Reading MLLM with Knowledge-Aware Reasoning on Public DataYuchuan Deng, Qijie Wei, Kaiheng Qian, Jiazhen Liu, Zijie Xin, Bangxiang Lan, Jingyu Liu, and 2 more authorspreprint arXiv:2604.08322, 2026The research addresses fundus imaging analysis for detecting retinal diseases. Rather than relying on proprietary clinical datasets, the authors developed a multimodal language model using publicly available data. Their approach incorporates two main innovations: a retrieval-augmented generation method for creating reasoning traces grounded in ophthalmic knowledge, and an enhanced reinforcement learning framework emphasizing trace consistency. Testing across multiple benchmarks demonstrated superior performance compared to baseline models and generic alternatives.

Generative Model
- Multi-Object Sketch Animation by Scene Decomposition and Motion PlanningIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
Sketch animation, which brings static sketches to life by generating dynamic video sequences, has found widespread applications in GIF design, cartoon production, and daily entertainment. While current sketch animation methods perform well in single-object sketch animation, they struggle in multi-object scenarios. By analyzing their failures, we summarize two challenges of transitioning from single-object to multi-object sketch animation: object-aware motion modeling and complex motion optimization. For multi-object sketch animation, we propose MoSketch based on iterative optimization through Score Distillation Sampling (SDS), without any other data for training. We propose four modules: LLM-based scene decomposition, LLM-based motion planning, motion refinement network and compositional SDS, to tackle the two challenges in a divide-and-conquer strategy. Extensive qualitative and quantitative experiments demonstrate the superiority of our method over existing sketch animation approaches. MoSketch takes a pioneering step towards multi-object sketch animation, opening new avenues for future research and applications.
-
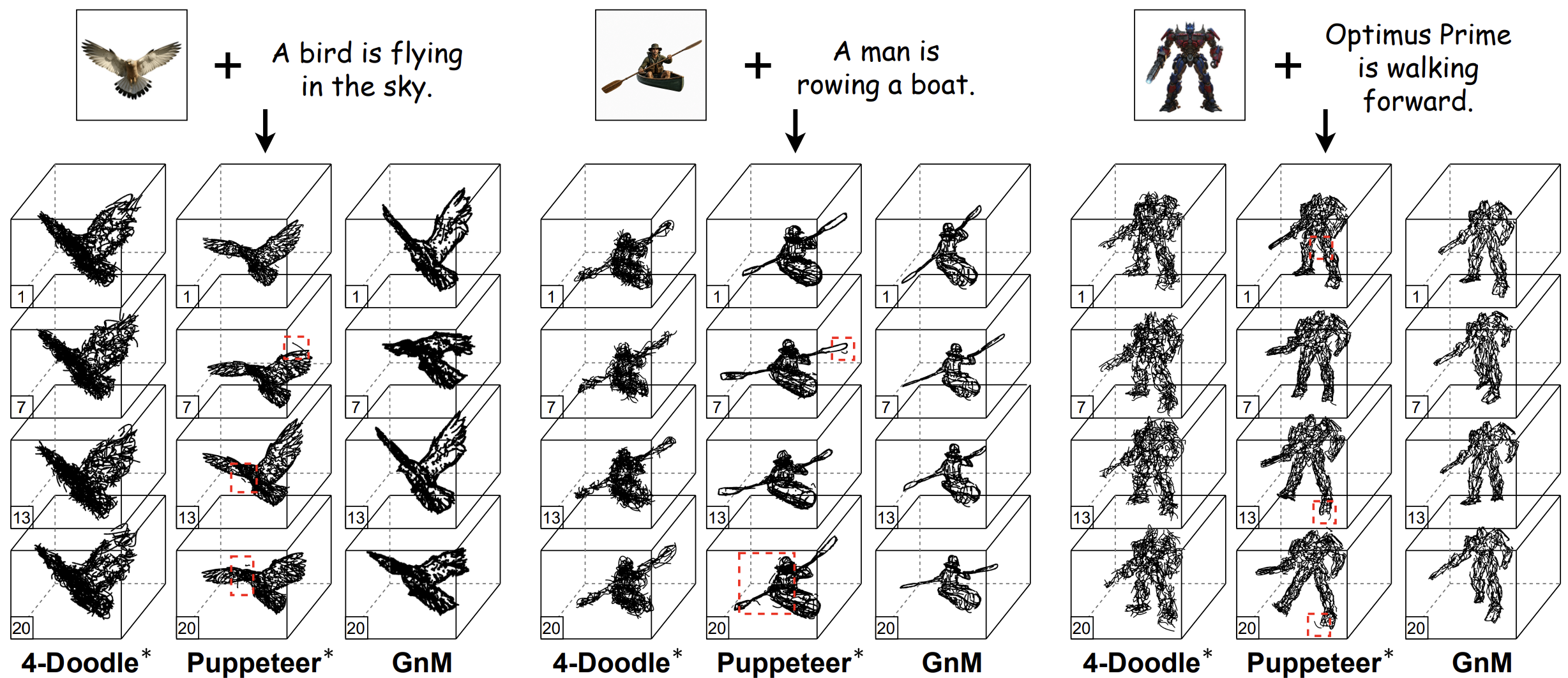 Creating a 4D Sketch from a Single ImageJingyu Liu, Shuo Gao, Zijie Xin, Ruixiang Zhao, Bangxiang Lan, Yuchuan Deng, Qingwei Shen, and 3 more authorsarXiv preprint, 2026
Creating a 4D Sketch from a Single ImageJingyu Liu, Shuo Gao, Zijie Xin, Ruixiang Zhao, Bangxiang Lan, Yuchuan Deng, Qingwei Shen, and 3 more authorsarXiv preprint, 2026

